
Afin de clôturer la série de billet sur la présence de Lecko à la conférence LeWeb Paris’12, intéressons-nous à la présentation par Google de sa nouvelle fonctionnalité : le Knowledge Graph. Une annonce qui pose une nouvelle fois la question des écarts de fonctionnalités entre moteur de recherche « classique » et moteur de recherche « d’entreprise ».
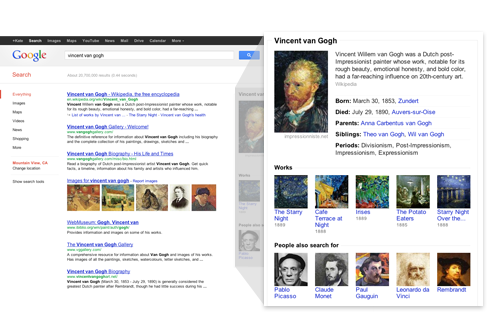
C’est lors de son passage que Ben Gomez (Vice-président de Google) a annoncé l’arrivée du Knowledge Graph en France. Pour ceux qui ne la connaîtraient pas encore, cette évolution consiste à rendre le moteur de recherche plus intelligent. En s’appuyant sur des données issues de différentes sources (Wikipedia et Freebase pour n’en citer que deux) et en les recoupant avec vos historiques de recherches, Google vous propose désormais une sorte de « fiche d’identité pertinente » des contenus recherchés. En d’autres termes, si vous tapez « Hôtel Costes » et que votre historique de recherche indique que vous êtes un fan d’électro, le Knowledge Graph vous proposera d’acheter les albums du même nom…et non une map vous indiquant où se situe le célèbre hôtel parisien. Avec ce nouveau service, Google étend encore un peu plus son champ d’action et sort du cadre des mots en s’attaquant aux contenus. Une évolution vers la sémantique qui a pour objectif à (très) long terme de faire de Google un moteur de recherche capable d’interpréter des demandes du quotidien, telles que « que reste-t-il dans mon frigo ? » (Une évolution intimement liée au développement de l’Internet des Objets).
Un mois après l’arrivée du Knowledge Graph, c’est au tour de Facebook de dévoiler son moteur de recherche. Lui aussi exploite les graphes sociaux, en se limitant toutefois aux données issues de votre réseau (pas de recherches sur le web donc). Une évolution que Facebook qualifie de « révolution » qui vient renforcer le mouvement initié par Google en direction d’une utilisation plus poussée des données sociales de chacun.

Ces annonces faites par les géants du web que sont Facebook et Google relance le débat quant au manque de « profilage » au sein des solutions professionnelles. En effet, ces dernières sont souvent très efficaces en termes d’indexation des données de l’entreprise mais ne proposent pas une approche centrée sur les utilisateurs. Les moteurs de recherche d’entreprise n’ont pas encore pris le virage du social et restent, dans leur grande majorité, incapables d’exploiter les graphes sociaux et les expertises d’un collaborateur pour lui faire remonter des contenus crédibles et lui suggérer des personnes pertinentes.
Pourquoi un tel constat ?
Tout d’abord, l’univers de l’entreprise est différent de celui du web en général : l’information contenue dans un système d’information est plus réduite et de meilleure qualité que celle contenue sur Internet…Les besoins ne sont donc pas les mêmes étant donné le niveau de pertinence plus élevé par nature des résultats issus des bases de données d’une entreprise. En effet, si un employé de la SNCF utilise le terme « voiture » lors d’une recherche, il est plus que probable qu’il s’agisse de trains aussi il ne semble pas très utile de disposer d’un outil permettant de faire le distinguo entre une automobile et un wagon.
Ensuite, la transversalité que permettent ces nouveaux moteurs de recherches plus sociaux se trouve bloquée par l’environnement particulier de l’entreprise. Cela requiert en effet de multiples connecteurs et de pouvoir utiliser l’ensemble des données dont on dispose or, les problématiques de droits d’accès inhérentes à la sphère professionnelle rendent complexe l’utilisation de nouveaux moteurs transversaux.
Le défi s’imposant aux entreprises semble donc d’abord de favoriser la mise en relation, et de permettre aux collaborateurs de mobiliser la ou les bonnes personnes sur la base de l’interprétation de leurs activités sociales (notamment les échanges informels auxquels ils participent).

Reste que les éditeurs de moteurs de recherche ont encore aujourd’hui du mal à aller au-delà de l’association individu/métadonnées que pourront ensuite exploiter les technologies traditionnelles. Il apparaît donc un certain retard, que viennent cependant nuancer les éditeurs de RSE plus à même de proposer une solution efficace de mise en relation. A l’instar de ce que propose désormais IBM Connection, il semble que ce soient les technologies de l’analytics adjointes aux RSE qui offrent aujourd’hui le plus de perspective.



